Neural Network [grade 6]
Mnist with CNN
grade 6: mnist classification of CNN Lenet version
Hooray! We are in the CNN stage.
Reasons for CNN: If you remember in our last post: mini version with Mnist, we implemented 2 hidden layers’ network manually, which could yield with accuracy of 97.5% with a 1000 hidden nodes layer. Which is great, but with one major defect, the training time is unbearable.
In short, with CNN, we will achieve better result with fewer training time. Something like a faster car with a lot of fuel-efficient.
Sounds fancy, but how does CNN make it?
In brief:
-
Partially connection, replace with full connection. With full connection, the calculation time is boosting, for e.g. we have input size of: 728 and hidden nodes of 1000, the weight matrix will be: 1000 * 728.
-
Share weights.
Biological intuition:
The implementation with Keras:
Following is the architecture of LeNet-5, if you found the link not available, try to google with “LeNet-5”.
We will implement LeNet 5 within Keras to have a quick show case:

# cnn lenet
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from keras import backend as K
# data read & format
batch_size = 128
num_classes = 10
epochs = 2
img_rows, img_cols = 28, 28
# read data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# reshape to add channel
if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
# normalize
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
# make class vectors into one-hot format
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# construct network structure
model = Sequential()
# C1 conv layer => S2 downsampling
model.add(Conv2D(6, (5, 5),
strides=(1,1),
activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2)))
# model.add(Dropout(0.25))
# C3 conv layer => S4 downampling
model.add(Conv2D(16, kernel_size=(5, 5),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
# C5 conv layer
model.add(Conv2D(120,(1,1),activation='relu'))
# F6 full connection layer
model.add(Flatten())
model.add(Dense(84,activation='relu'))
# classification
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=batch_size,
epochs=epochs,verbose=1,
validation_data=(x_test,y_test))
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
As usual, we will run a performance test. We tweaked the original LeNet implementation a little bit, switched optimizer to Adadelta, average pooling to max pooling and the activation function from tanh to relu.
We use the original parameter and methodologies as benchmark, ran each setting with 12 epoches, following is the result:
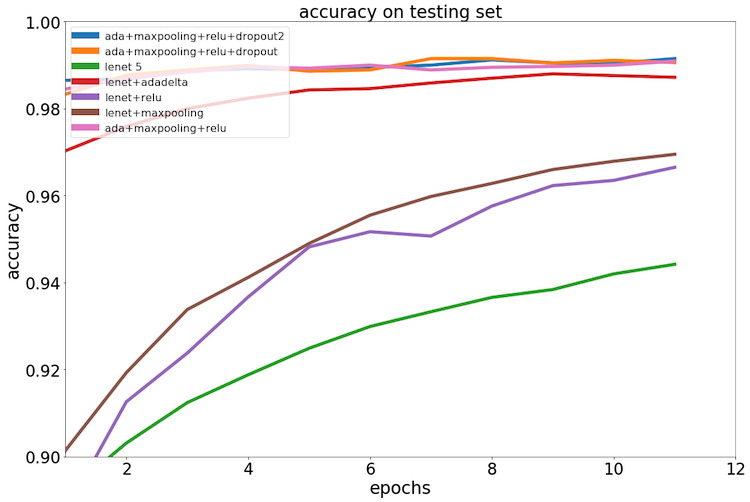
Read from the image, we could see that, with adadelta, relu and max pooling, we could yield with best performance. The factor that adding drop out or not does not make a significant difference(We did run a validation to check on statistic significance).
Among the single factors of : using adadelta, relu and max pooling, we could see the adadelta made the most contribution on performance improving.
The testing data groups are not in normal distribution, we ran a Wilcoxon signed-rank test, to see if the adadelta group has no difference with top layer groups and benchmark groups, the p value indicates the null hypothesis could be rejected.
By this post, would like send respects to Yann Lecun in 1998, LeNet 5 did amazing job in that time and is true pioneer of CNN and deep neural networks.
And wait, We are not calling this is an end of the post, still, we will implement LeNet 5 from scratch with numpy.
[post status: half done]